
Quantum Computers Could Revolutionize AI. Really. Google Quantum AI Just Proved It. On Paper.

Quantum computing has a problem that rarely makes the headlines. After thirty-two years of research, tens of billions of dollars in government and corporate investment, and enough PhD dissertations to fill a small library, the field has produced exactly three broad classes of problems where a quantum computer offers a proven, substantial advantage over a classical one: factoring integers (Shor, 1994), simulating quantum systems (Lloyd, 1996, building on Feynman’s 1982 insight), and searching unstructured databases (Grover, 1996, whose quadratic speedup is provably optimal, meaning it is as modest as a quantum advantage can be while still existing). Everything else has been either a subroutine, a variation on one of these three, or a proposal that was subsequently dequantized, meaning a classical algorithm was found that matched it. Three ideas in three decades. The machine does not yet exist, and the list of things it would be good for, once it does, fits on a napkin.
This month, a team at Google Quantum AI, led by Hsin-Yuan Huang and including John Preskill and Ryan Babbush, may have added a fourth item to that napkin. In a 144-page paper, they prove that a quantum computer with fewer than sixty logical qubits could outperform classical machines by four to six orders of magnitude on standard machine learning tasks. The theorems are unconditional, the proofs information-theoretic, the mathematics relying on nothing beyond the principle of superposition. The results hold even if polynomial-time quantum computation turns out to be equivalent to classical computation. Even, that is, if the quantum computer offers zero time advantage at all.
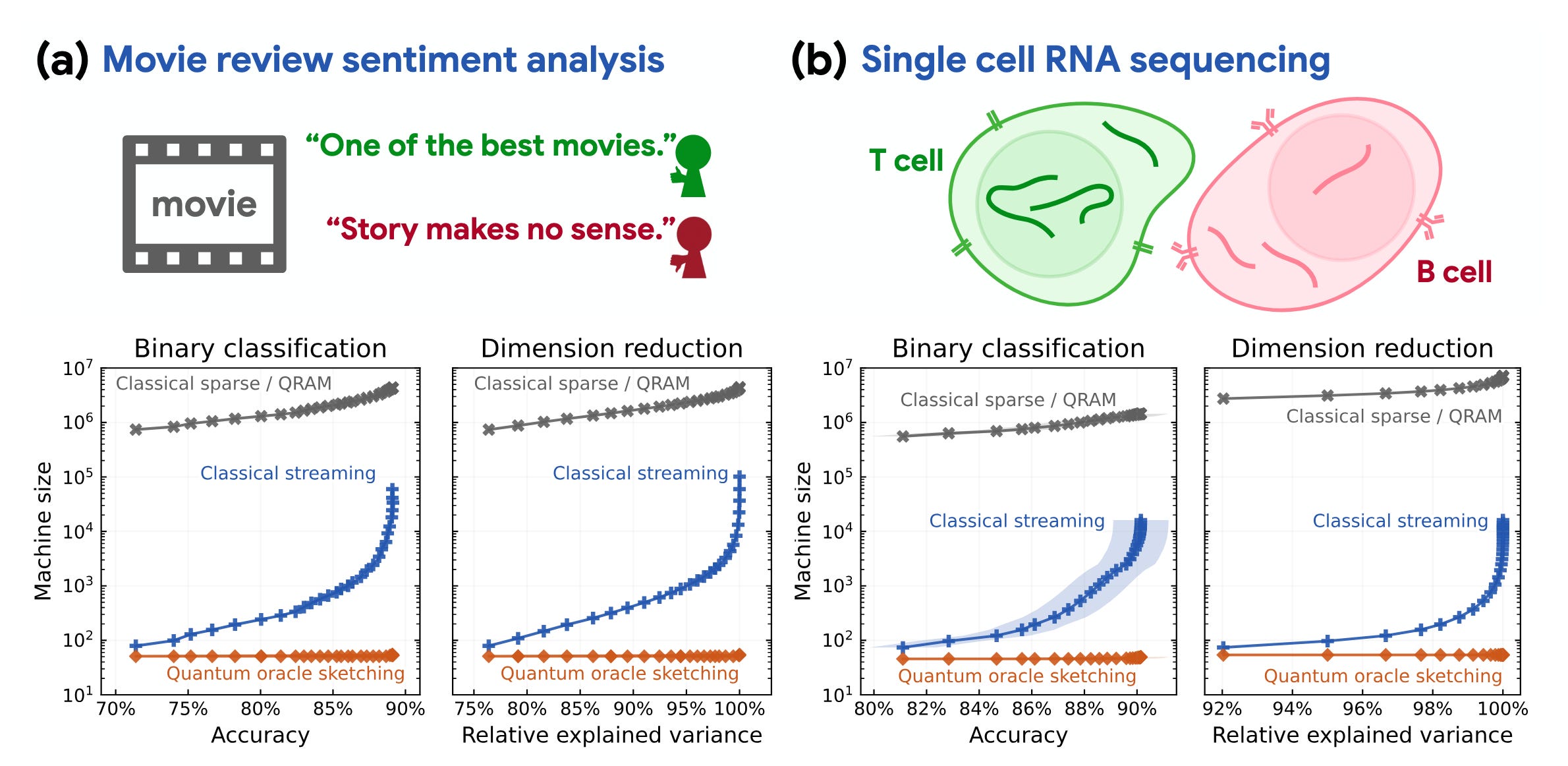
The paper proves a memory compression, not a speedup: sixty qubits doing the work of classical machines millions of times larger. The time complexity is the same order as classical, dominated by data loading. This is why the result survives even if quantum computers turn out to offer zero time advantage over classical ones, a scenario that would kill Shor's algorithm and quantum simulation at a stroke. Those advantages are about speed. This one is about compression.
If quantum oracle sketching survives scrutiny, this is genuinely significant. Machine learning on classical data would become the fourth entry on a very short list. Four useful ideas in thirty-two years remains a remarkable ratio of effort to output, and adding a new one deserves real credit.
What would the algorithm do? Classification of movie reviews. Dimensionality reduction of single-cell RNA data. Solving linear systems. The technique sidesteps the old bottleneck of loading classical data into a quantum machine by building coherent quantum access from a stream of classical samples, each processed once and discarded. Combined with classical shadow tomography for readout, it constructs compact classical models from massive datasets, a task the authors prove is impossible for any classical machine without exponentially more memory.
The catch is in a single subordinate clause on page 23: “extrapolating this scaling, while ignoring the exponential runtime overhead.”
Every “numerical experiment” in the paper is a classical simulation of a quantum circuit, run in JAX on Google’s own TPUs. The real-world datasets are real, but the quantum algorithm processing them lives on paper. The sixty logical qubits are a resource count for a machine that, on current architectures, would require hundreds of thousands of physical qubits operating below the error-correction threshold. The paper is 144 pages of rigorous, beautiful mathematics describing what you could do with an instrument that does not exist and that nobody knows how to build.
The result is a quantum space advantage, a proof that quantum Hilbert space can compress information more efficiently than classical memory. The question it answers is: if you already had a fault-tolerant quantum computer, what could you do with it? The question it declines to address is: can you build one? That second question, the one about the apparatus, is the entire engineering problem of quantum computing, the problem that has consumed thirty years and tens of billions of dollars, the problem that Willow’s single logical qubit at distance seven took a step toward answering in December 2024 and that remains, by any honest accounting, decades from resolution.
A philosopher of physics named Itamar Pitowsky understood this distinction in 1990, six years before anyone had built a working qubit. Quantum mechanics, Pitowsky observed, gives you unbounded parallelism in encoding information. The difficulty lives entirely in retrieval: constructing the measurement apparatus that extracts the answer with high probability. Superposition by itself buys you nothing. A naive quantum search of all possible solutions collapses, upon measurement, to a single random outcome, with the same probability as a classical coin flip. The advantage arrives only when someone engineers a specific superposition whose probability distribution, shaped by interference, concentrates on the correct answer. That engineering depends on the mathematical structure of the problem. It is problem-specific, and it is hard.
The Google paper confirms every word of that analysis. The quantum oracle sketching algorithm works because certain ML tasks have enough mathematical structure to permit efficient extraction via quantum singular value transforms. The paper’s own discussion acknowledges this: “the relevant information has sufficient structure to permit its efficient extraction.” Replace “sufficient structure” with “a clever superposition” and you have Pitowsky’s formulation from 2002, verbatim in spirit.
So why publish 144 pages of theory for a machine that cannot yet run the algorithm? Because this is what Google Quantum AI can do right now. They can prove theorems. They can stake a claim. Google is spending billions on quantum hardware that currently solves zero practical problems. The supremacy demonstration (2019) proved a quantum computer could do something a classical computer could not, and the something was useless. Telling your board that the first killer application is breaking encryption carries complications of its own. Machine learning is the answer that aligns with Google’s core business. The paper is a promissory note, issued in the currency of mathematics, redeemable upon delivery of hardware that the authors themselves cannot specify a timeline for.
The question remains what it has always been: can you build the apparatus?